مدل هوش مصنوعی متنباز ImageBind دادههای ورودی مختلفی مثل صدا، تصویر، ویدیو و دما را به هم پیوند میزند.
به گزارش ایرانی متا، دیجیاتو نوشت: متا از مدل هوش مصنوعی جدیدی رونمایی کرده است که چندین جریان داده مختلف ازجمله متن، صدا، تصویر، دما و اطلاعات حرکتی را به یکدیگر پیوند میدهد. این مدل که ImageBind نام دارد، بهصورت متنباز در دسترس عموم قرار میگیرد و سعی میکند مانند انسان رابطه میان دادهها را پیشبینی کند.
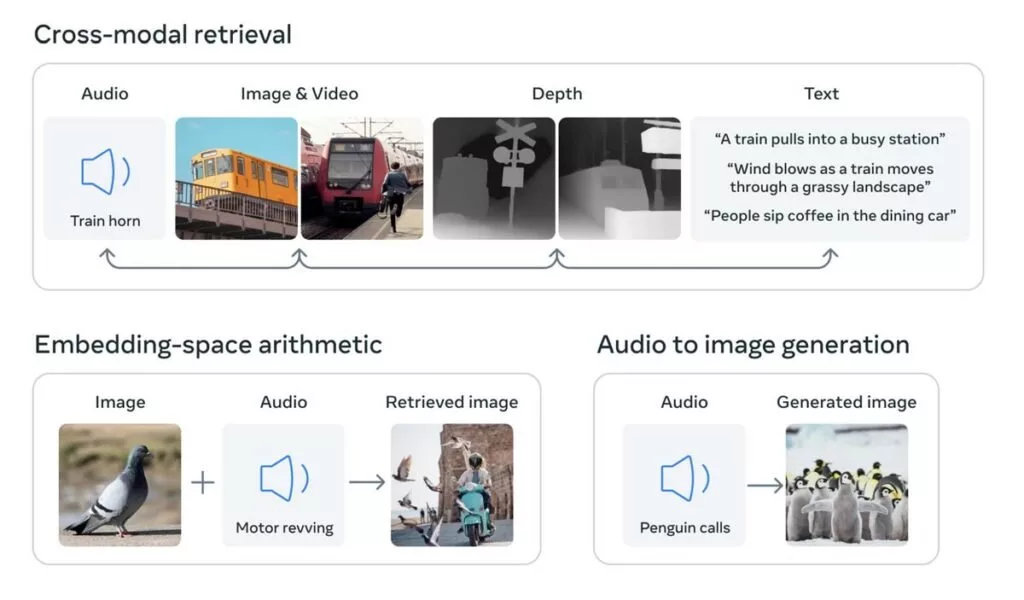
مدلهایی مثل میدجرنی، Stable Diffusion و DALL-E 2 کلمات را با تصاویر پیوند میدهند تا امکان خلق تصاویر جدید با توصیفات متنی فراهم شود. اما ImageBind قابلیتهای وسیعتری دارد. این مدل هوش مصنوعی میتواند میان 6 نوع داده شامل متن، تصویر یا ویدیو، صدا، اندازهگیریهای سهبعدی (عمق)، اطلاعات دمایی (حرارت) و دادههای حرکتی (IMU یا واحد اندازهگیری اینرسی که مثلاً در گوشیهای هوشمند برای تشخیص تغییر حالت دستگاه از عمودی به افقی استفاده میشود) پیوند ایجاد کند.
این کار در شرایطی انجام میشود که لازم نیست تمام احتمالات ممکن از قبل به هوش مصنوعی آموزش داده شود. میتوانید ImageBind را بهعنوان یک سیستم یادگیری ماشینی در نظر بگیرید که شباهت بیشتری به یادگیری انسانی دارد. برای مثال، اگر شما در یک محیط شلوغ مثل خیابان ایستاده باشید، مغزتان (عمدتاً بهطور ناخودآگاه) محیط را میبیند و صداها را میشنود تا متوجه عبور خودروها، عابران پیاده، ساختمانها، وضعیت آبوهوا و غیره شود.
مدل متا ImageBind چگونه کار میکند؟
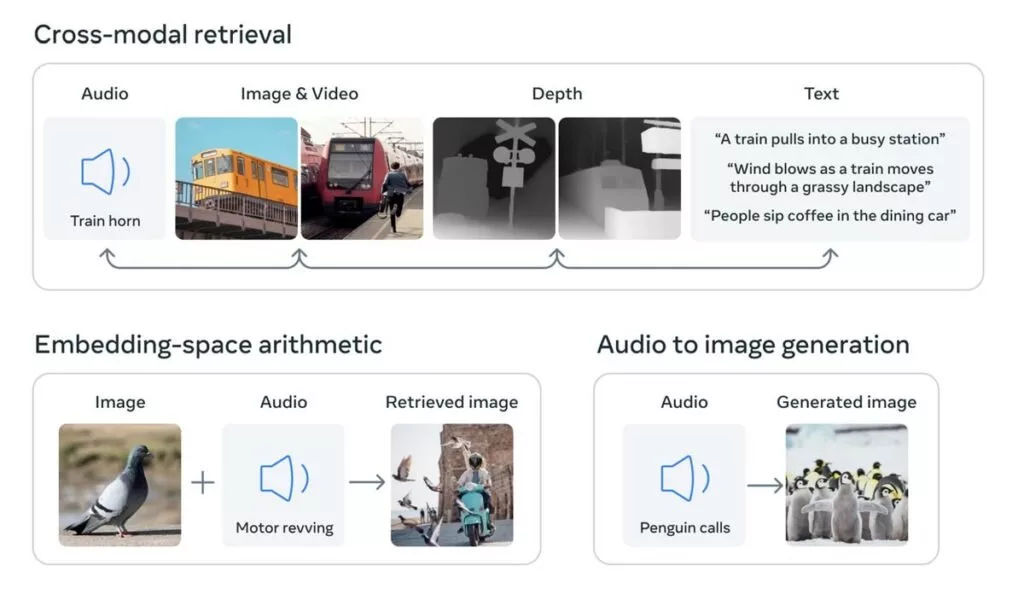
حالا کامپیوترها هم بیشتر بهسمت شبیهسازی رابطه میان حواس مختلف انسانی رفتهاند تا میان دادههای ورودی مختلف پیوند ایجاد کنند. اگر توصیف «یک سگ شکاری با لباسهای گندالف که سعی دارد تعادلش را روی یک توپ حفظ کند» را به میدجرنی بدهید و یک تصویر واقعگرایانه از این صحنه دریافت کنید، در طرف مقابل با یک مدل هوش مصنوعی چندوجهی مثل ImageBind احتمالاً میتوانید ویدیویی از یک سگ با صداهای مربوطه، مثلاً در یک محیط شهری، بسازید که در اتاقی با دمای مشخص حضور دارد.
ازجمله کاربردهای این مدل قدرتمند میتوان به دنیای واقعیت مجازی و متاورس اشاره کرد. برای مثال، در آینده احتمالاً هدستی تولید خواهد شد که بتواند درلحظه یک صحنه سهبعدی واقعی را با مشخصات معین خلق کند.
متا انتظار دارد که این مدل هوش مصنوعی در آینده تعداد «حواس» خود را از شش عدد افزایش دهد. محققان این شرکت میگویند پشتیبانی از حسهایی مثل لامسه، تکلم، بویایی و حتی سیگنالهای fMRI مغزی میتواند به غنیترکردن تجربه استفاده از این مدلها کمک کند. منتها درحالحاضر بهنظر میرسد که هوش مصنوعی جدید متا بیشتر برای امور تحقیقاتی کاربرد داشته باشد.